Esta função permite extrair informações de uma URL da internet, automatizando a coleta de dados de websites. É ideal para monitoramento de conteúdo, análise competitiva e agregação de dados para pesquisa.
Campos de Preenchimento:
Insira a URL: Forneça a URL do site/página do qual você deseja extrair informações. Certifique-se de que a URL seja acessível e válida.
Resultado de Output:
As informações do site/página serão extraídas. Um ponto importante é que somente informações de texto serão extraídas, não sendo possível ler as imagens.
Casos de Uso:
1. Monitoramento de Notícias: Utilize para extrair as últimas notícias de portais de informação para análise de tendências.
2. Análise Competitiva: Extraia preços, descrições de produtos e outras informações de sites de concorrentes para comparação de mercado.
3. Estudo de Mercado: Colete dados de publicações e pesquisas de mercado para auxiliar na tomada de decisão.Limitações:
O Web Scraper respeita as políticas de robots.txt dos sites, portanto, algumas páginas podem não permitir a raspagem de dados. Além disso, a eficácia da extração pode variar dependendo da estrutura do site e das mudanças no layout ou no código HTML. Uma observação é que este step não pode extrair informações de ambientes logados.
Um fator importante é que as imagens não são processadas com o Web Scraper.
Exemplos de Implementação:
Caso 1: Análise e Resumo de Sites: Obtenha um resumo de conteúdo e uma avaliação do Tempo de leitura, Legibilidade e Segurança do site.
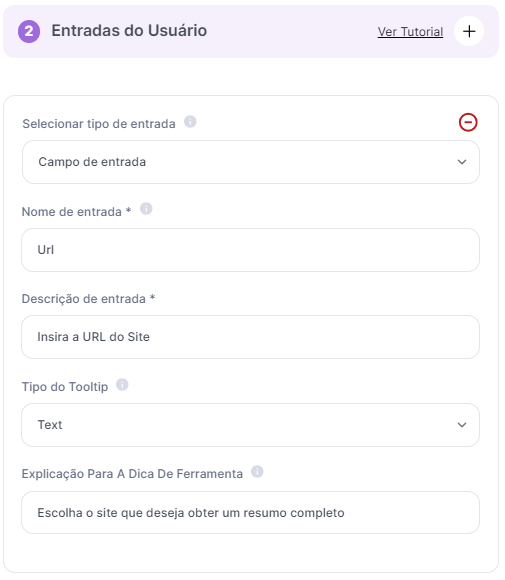
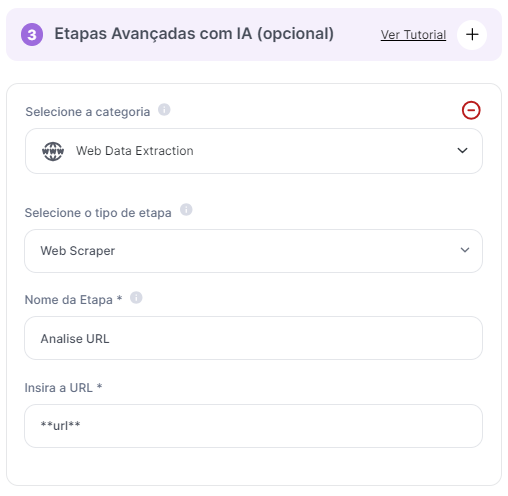
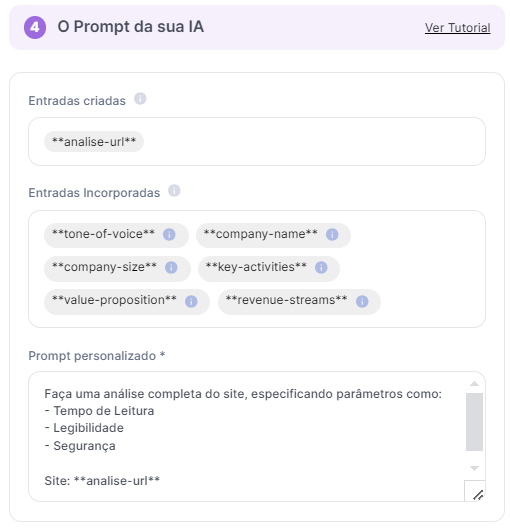
Caso 2: Comparação de Preços: Uma empresa utiliza a ferramenta para extrair preços de produtos de diversos e-commerces para ajustar sua estratégia de precificação.
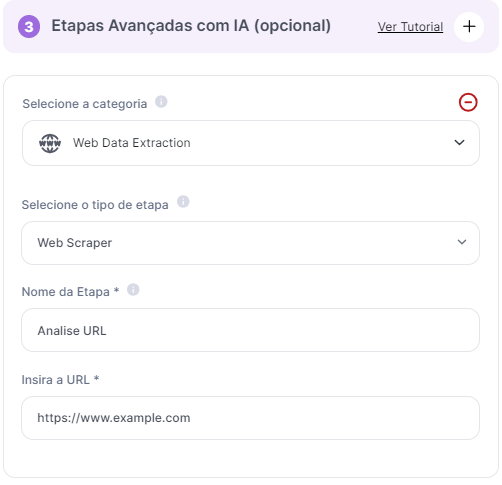
Conclusão:
A função "Web Scraper" é uma ferramenta poderosa na Tess AI para a extração automática de dados de websites, facilitando a coleta de informações valiosas para diversas aplicações, desde monitoramento de conteúdo até análises competitivas e acadêmicas.