Esta função permite extrair texto de páginas específicas de um documento PDF. É útil para focar em seções particulares de um documento sem necessidade de processar o arquivo inteiro, economizando tempo e recursos.
Campos de Preenchimento:
Insira o arquivo ou link PDF: Forneça um link para um arquivo PDF acessível publicamente. Alternativamente, você pode usar o resultado da entrada do usuário "Subir Arquivo" para extrair dados de arquivos armazenados em seu computador.
Especifique as Páginas: Indique quais páginas do PDF você deseja extrair o texto. Você pode inserir um único número de página, um intervalo ou uma lista separada por vírgulas.
Resultado de Output:
O texto das páginas especificadas será extraído.
Casos de Uso:
1. Análise de Capítulos Específicos: Ideal para estudantes e pesquisadores que precisam analisar capítulos específicos de livros acadêmicos.
2. Revisão de Documentos Legais: Permite a advogados revisar rapidamente cláusulas específicas em contratos extensos.
3. Compilação de Informações Setoriais: Facilita a coleta de informações de determinadas seções de relatórios anuais ou documentos técnicos para análise de mercado.Limitações:
É importante ter em mente que o treinamento de sua IA com base em documentos PDF extraídos por meio do Tess AI possui uma limitação de tamanho.
O treinamento não pode ultrapassar 80.000 palavras. Portanto, certifique-se de que o PDF selecionado esteja dentro deste limite. Caso você tenha um PDF com mais de 80.000 palavras, considere dividi-lo em partes menores ou selecionar apenas as seções mais relevantes.
Exemplos de Implementação:
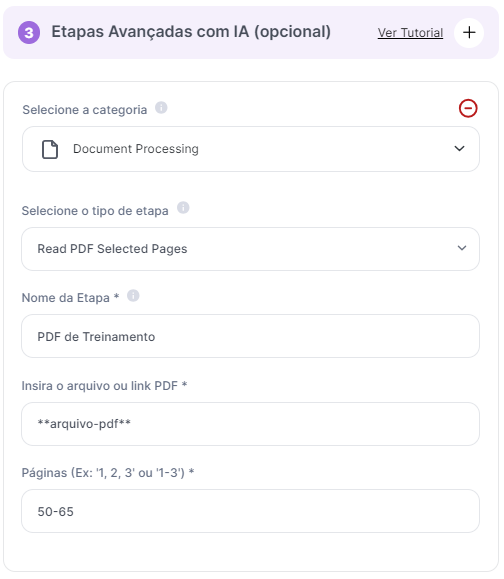
Caso 1: Análise de Seções de Livro: Um usuário carrega um PDF de um livro e especifica que apenas as páginas do capítulo 3 sejam lidas para focar em um tema específico.
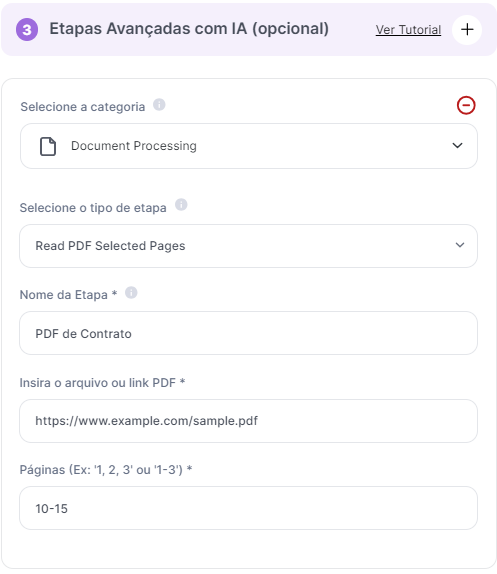
Caso 2: Consulta de Cláusulas Contratuais: Um advogado usa um link fixo para um contrato e extrai apenas as páginas contendo cláusulas de interesse para revisão rápida.
Conclusão:
A função "Read PDF Selected Pages" é um step valioso na Tess AI para extrair texto de páginas específicas de documentos PDF, permitindo uma análise mais direcionada e eficiente de informações relevantes sem a necessidade de processar documentos inteiros.